[cB] - Vector Databases
A vector database is a type of database that indexes and stores vector embeddings for fast retrieval and similarity search, with CRUD operation capabilities
What is a vector database and why is it needed?
A vector database (also known as a spatial database) is a database that is optimized to store and query data related to objects in geometric space. Some key things to know about vector databases.
However in context of LLMs , vector databases have a different meaning than traditional spatial vector databases . For LLMs like GPT-3, a vector database refers to the database used internally to store the enormous vector representations for words, sentences, paragraphs, and documents that the model has learned.
These vector representations are called vector embeddings.
Vector Embeddings
Before delving into vector databases lets understand what are vector embeddings first.
A vector is a mathematical structure with a size and a direction
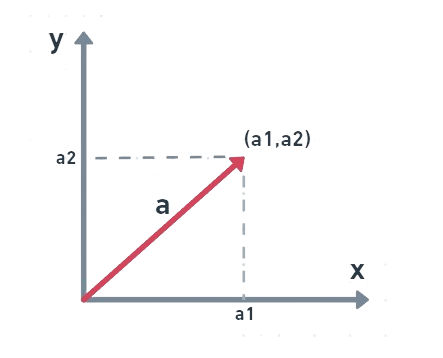
But why do we need such a structure for machine learning and large language models?
As CPUs and GPUs are optimized to perform the mathematical operations. Therefore it makes sense to use mathematical operations for maximum efficiency.
So there is a need to convert our data into vector representations so it can be used by the models effectively
Vector embedding is a technique/process to convert normal data into vector representation and these representations in turn are called vector embeddings.
To create vector embeddings we use models called embedding models. Embedding models are essentially partial neural networks which has a layer that creates the embedding .
Creating an embedding model , similar to neural networks requires some manual effort / supervised learning. Feeding the network a large set of training data made of pairs of inputs and labeled outputs. Alternatively, we can apply self-supervised or unsupervised learning either of which doesn’t require labeled outputs. These values are transformed with each layer of network activations and operations. With every iteration of training, the neural network modifies the activations in each layer. Eventually, it can predict what an output label should be for a given input.
But this output layer is removed in case of embedding models .

So what is a vector database?
A vector database stores the generated embeddings from the content, along with the original data and some metadata.
Then we can query this data to obtain results.
Also one thing that separates vector databases from normal databases is that it operates on the basis of similarity of the embeddings rather than actual exact results.
A vector database uses a combination of different algorithms that all participate in Approximate Nearest Neighbor (ANN) search. These algorithms optimize the search through hashing, quantization, or graph-based search.
These algorithms are assembled into a pipeline that provides fast and accurate retrieval of the neighbors of a queried vector. Since the vector database provides approximate results, the main trade-offs we consider are between accuracy and speed. The more accurate the result, the slower the query will be.
In general all vector databases follow a similar pipeline of.
- Indexing - The vectors are indexed using one of the indexing algorithms for fast searching.
- Querying - The vector database compares the indexed query vector to the indexed vectors in the dataset to find the nearest neighbors
- Post Processing - Sometimes the results go through a post processing stage. for example reranking

Vector Indexing Algorithms
Some of the common vector indexing algorithms are.
Flat Indexing - In flat indexing we simply store each vector as is, with no modifications.
Flat indexing is simple, easy to implement, and provides perfect accuracy. The downside is it is slow. In a flat index, the similarity between the query vector and every other vector in the index is computed.
We then return the K vectors with the smallest similarity score.
Flat indexing is the right choice when perfect accuracy is required and speed is not a consideration. If the dataset we are searching is small, flat indexing may also be a good choice as the search speed can still be reasonable.
Locality Sensitive Hashing (LSH) indexes - Locality Sensitive Hashing is an indexing strategy that optimizes for speed and finding an approximate nearest neighbor, instead of doing an exhaustive search to find the actual nearest neighbor as is done with flat indexing.
The index is built using a hashing function. Vector embeddings that are nearby each other are hashed to the same bucket. We can then store all these similar vectors in a single table or bucket.
When a query vector is provided, its nearest neighbors can be found by hashing the query vector, and then computing the similarity metric for all the vectors in the table for all other vectors that hashed to the same value. This results in a much smaller search compared to flat indexing where the similarity metric is computed over the whole space, greatly increasing the speed of the query.
Inverted file (IVF) indexes - Inverted file (IVF) indexes are similar to LSH in that the goal is to first map the query vector to a smaller subset of the vector space and then only search that smaller space for approximate nearest neighbors. This will greatly reduce the number of vectors we need to compare the query vector to, and thus speed up our ANN search.
In LSH that subset of vectors was produced by a hashing function. In IVF, the vector space is first partitioned or clustered, and then centroids of each cluster are found. For a given query vector, we then find the closest centroid. Then for that centroid, we search all the vectors in the associated cluster.
Note that there is a potential problem when the query vector is near the edge of multiple clusters. In this case, the nearest vectors may be in the neighboring cluster. In these cases, we generally need to search multiple clusters.
Hierarchical Navigable Small Worlds (HNSW) indexes - Hierarchical Navigable Small World (HNSW) is one of the most popular algorithms for building a vector index. It is very fast and efficient.
HNSW is a multi-layered graph approach to indexing data. At the lowest level, every vector in the index is captured. As we move up layers in the graph, data points are grouped together based on similarity to exponentially reduce the number of data points in each layer. In a single layer, points are connected based on their similarity. Data points in each layer are also connected to data points in the next layer.
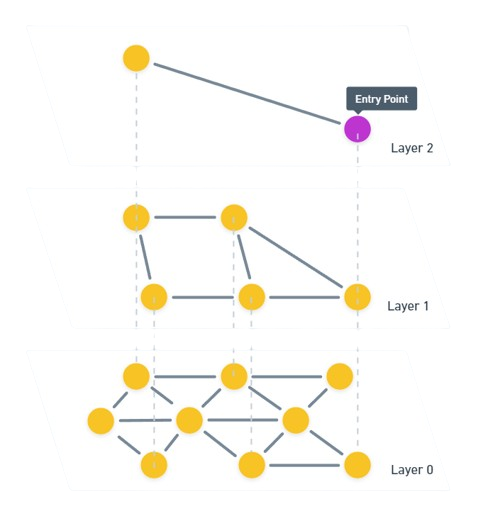
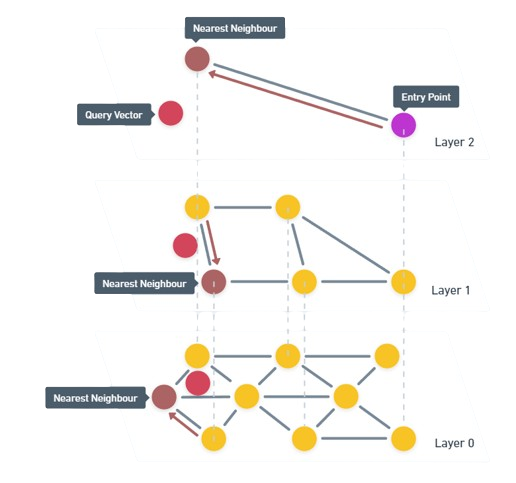
To search the index, we first search for the highest layer of the graph. The closest match from this graph is then taken to the next layer down where we again find the closest matches to the query vector. We continue this process until we reach the lowest layer in the graph.
Vector database use cases
Similarity and semantic search
One of the most common use cases for a vector database is in providing similarity or semantic search capabilities, because it provides a native ability to encode, store and retrieve information based on how it relates to the data around it. By using a vector database to store your corpus of data, applications can gain access to not just how the data relates to other data but how it is semantically similar or different from all the other data within the system.
Machine learning and deep learning
Probably the most common implementation of this is building chatbots that use natural language processing to provide a more natural interaction. From customer information to product documentation, leveraging a vector database to store all of the relevant information provides machine learning applications with the ability to store, organize and retrieve information from transferred learning and allows for more efficient fine-tuning of pre-trained models.
Large language models (LLMs) and generative AI
Leveraging a vector database for generative AI applications and large language models (LLMs), like other use cases, provides the foundation by providing storage and retrieval of large corpuses of data for semantic search. Beyond that however, leveraging a vector database provides for content expansion allowing for LLMs to grow beyond the original pre-trained data. In addition, a vector database provides the added abilities of providing dynamic content retrieval and the ability to incorporate multi-model approaches where applications can bring together text and image modalities for increased engagement.
Recommendation engines
While recommendation engines have been mainstream for a significant time, leveraging a vector database provides exponentially more paths where recommendations can be made. Previous models for recommendation engines used keyword and relational semantics, but with a vector database recommendations can be made on high-dimensional semantic relationships leveraging hierarchical nearest neighbor searching to provide the most relevant and timely information.
Best Vector Databases Available
Some of the best vector databases available right now are.
- Chroma - https://www.trychroma.com
- Pinecone - https://www.pinecone.io
- Weaviate - https://weaviate.io
- Faiss - https://github.com/facebookresearch/faiss
- Qdrant - https://qdrant.tech
ok